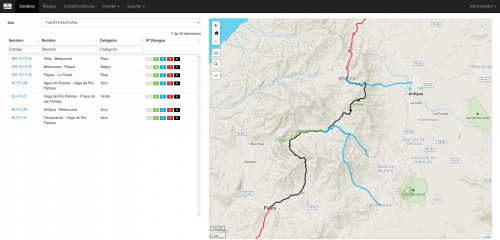
In the project “Validation of the Methodology of the Identification and Characterisation of Risks on Pathways in the Canary Islands”, carried out by the government of the Canary Islands, iCarto participated as technical support specialised in geographic information technologies, designing an ETL (Extract, Transform and Load) system that enables data gathered on the ground to be validated and added to a geographic database. Later, a series of calculations on raster and vector data are implemented via PostGIS functions, allowing us to obtain indicators and categorise the pathways.

Problems posed by the project
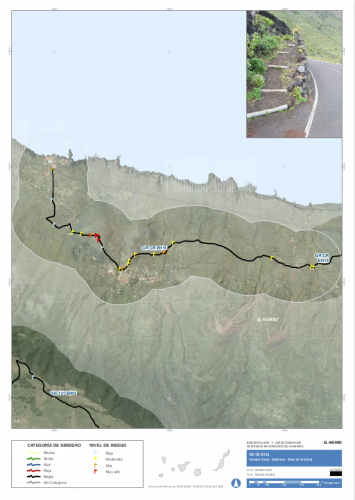
In the framework of the European project CAMINMAC, the town council of Tenerife carried out a task in May 2015 the purpose of which was the “Identification of Risks, Assessment and List of Preventive and Corrective Measures on the Pathways on the Island of Tenerife”. In 2016, the government of the Canary Islands commissioned the project “Validation of the Methodology of the Identification and Characterisation of Risks on Pathways in the Canary Islands”. The scope of the project included “the development of a spatial database”, which was implemented by Mariano Sanz Gil and iCarto.
The work was based on the data gathered on the ground, while tools and technology continued to advance, thus making them liable to vary in terms of characterisation.
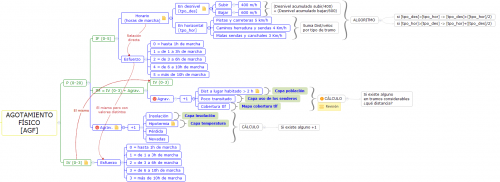
We also needed a methodology to characterise different kinds of risks (physical exhaustion, falls, car accidents, etc.) in specific locations or sections of a pathway. A text-based description to generate a risk rating for each incidence based on field observations and other information (height, distance to inhabited areas, etc.), and a way of categorising the pathways by risk and other criteria.

And how we solved them
The project not only consisted in ‘creating’ a database, but also in validating, implementing and evolving the proposed initial methodology with computer-based algorithms. In this context, the data itself and its form would increase over time.
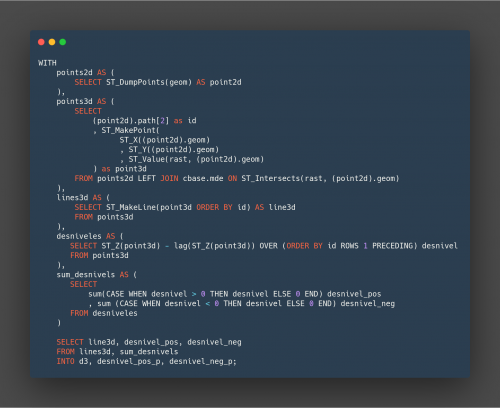
A custom ETL pipeline/system was designed using Python and SQL, which made it possible to pre-validate/validate the field data, enter them into the database along with the rest of the necessary information, run the algorithms and automatically generate an analysis. This system enables all or part of the process to be run with barely any human intervention, and can therefore adapt to changing data and methodology.
The calculations of the indicators and the categorisation itself, which includes operations on raster and vector information, are implemented using functions on the PostgreSQL/PostGIS database as per the client’s request, and also in order to be able to separate the generation and exploitation of the information from the algorithms themselves. Some of the calculation techniques were inspired by dynamic segmentation and linear referencing (since these were unsuitable for direct use in this case) and an architecture that makes it easy to add or remove new types of risks, specific observations or to modify the methodology parameters.