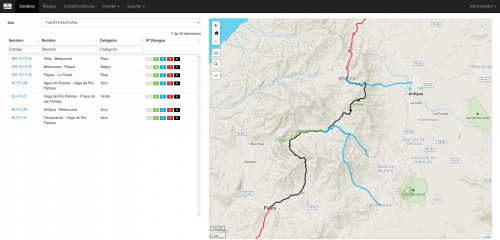
Dentro del proyecto «Validación de la metodología de la identificación y caracterización de riesgos en senderos en Canarias» llevado a cabo por el Gobierno de Canarias, iCarto participa como apoyo técnico especializado en tecnologías de información geográfica, diseñando un sistema ETL (Extract, Transform and Load), que permite validar e incorporar a una base de datos geográfica datos tomados en campo. Posteriormente se implementan mediante funciones en PostGIS una serie de cálculos sobre datos ráster y vectoriales que permiten obtener indicadores y categorizar los senderos.

Cuál era el problema del proyecto
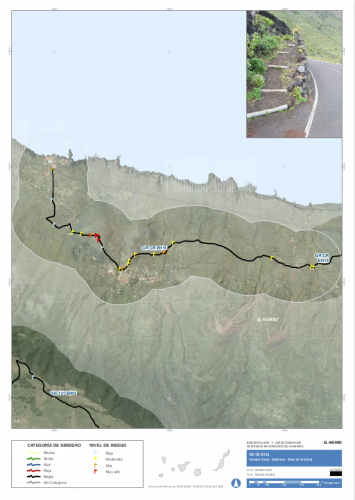
En el marco del proyecto europeo CAMINMAC el Cabildo de Tenerife realizó en mayo de 2015 un trabajo cuyo fin fue la «Identificación de riesgos, valoración y relación de medidas preventivas y correctoras en los senderos de la isla de Tenerife». En 2016 el Gobierno de Canarias encarga la «Validación de la metodología de la identificación y caracterización de riesgos en senderos en Canarias». Dentro de la finalidad del encargo se incluye «el desarrollo de una Base de Datos Espacial». Trabajo que es implementado por Mariano Sanz Gil e iCarto.
Se parte por un lado de los datos que se toman en campo al mismo tiempo que evolucionan las herramientas y la metodología y por tanto susceptibles de variar en cuanto a su caracterización.
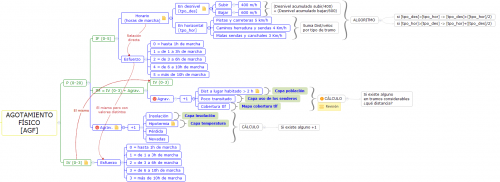
Y por otro de una metodología para caracterizar distintos tipos de riesgos (agotamiento físico, caídas, atropellos, …) en puntos concretos o tramos de un sendero. Una descripción textual para la generación de un índice de riesgo para cada incidencia en base a las observaciones de campo y otra información (altitud, distancia a núcleos habitados, …). Y una forma de categorizar los senderos en base a estos riesgos y otros criterios.

Y cómo lo solucionamos
El proyecto no consistía únicamente en «crear» una base de datos si no que era necesario a su vez validar, implementar y evolucionar la metodología inicial propuesta mediante algoritmos informáticos. En un contexto en el que los propios datos y su forma irían incrementándose en el tiempo.
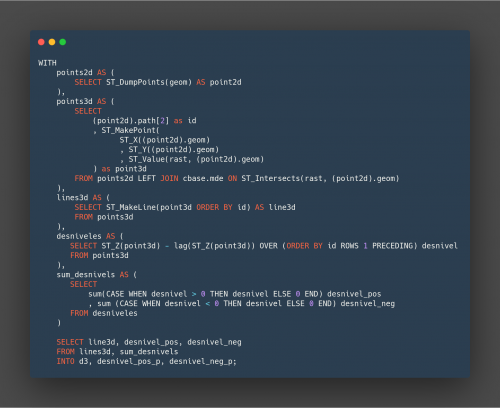
Se diseña un sistema pipeline/ETL a medida mediante Python y SQL que permite (pre)validar los datos de campo, insertarlos junto al resto de información necesaria en la base de datos, ejecutar los algoritmos y generar analísis de forma automática. Esto permite ejecutar todo el proceso o una parte del mismo sin apenas intervención humana pudiendo adaptarse a datos y metodología cambiantes.
Los cálculos de los indicadores y la categorización en sí que incluye operaciones sobre información ráster y vectorial están implementados mediantes funciones en la propia base de datos PostgreSQL/PostGIS por requisito del cliente y para poder independizar las herramientas de generación y explotación de la información de los algoritmos en sí. Algunas de las técnicas de cálculo se inspiraron en la Segmentación Dinámica y la Referenciación Lineal (que no eran apropiadas de usar directamente para esta caso) y una arquitectura que permitera de forma asequible añadir o eliminar nuevos tipos de riesgos, observaciones concretas o variar los parámetros de la metodología.